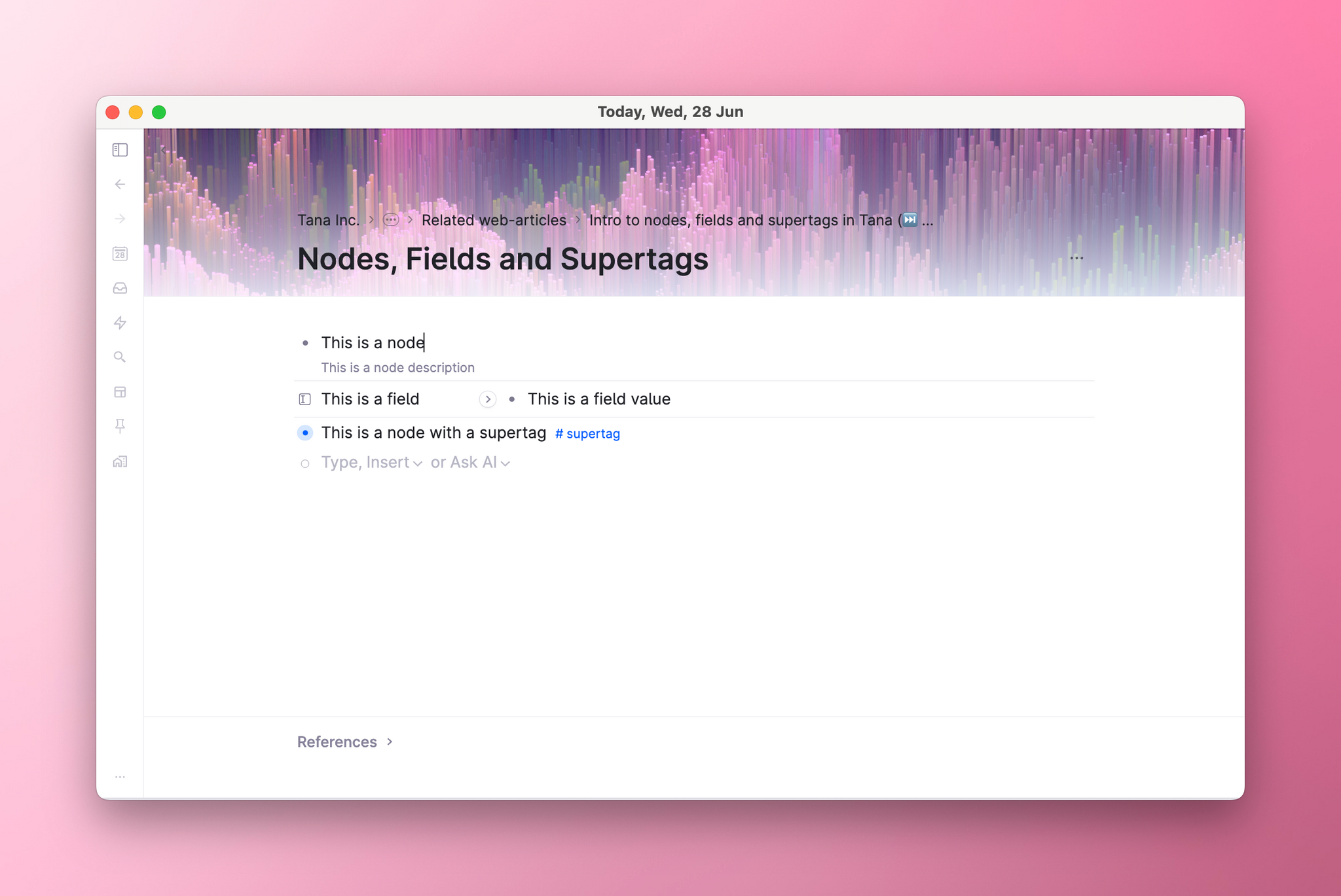
Fields store structured information in Tana. They provide additional details about nodes such as their status, launch dates, social media profiles, order numbers, attendees, comments - anything you want to consistently record in the same way, everywhere.
Use fields to describe your data. For a Person, you may add fields (prefixed with > ; this also creates a field in Tana) like >Name, >Number, >Email, >Address, >Social media, all of which helps organize information concerning that person. One way to check if a field is right, is to think "has a" when adding fields. A person has an Email. A task has a Due date. A movie has a Release date.
Fields are like the columns of a database. Every node is a database entry, and the fields are consistent information about that node. You'll see this when you use our Table view.
Fields can be added to any node but even better is using our Supertags to create a template of fields you want applied every time you record a new #Person, #Task, or #Movie. See Supertags for more.
Fields help you resurface, sort, group and filter your information. Find all your #Ideas that have >Topic: Architecture. Filter #Movies by >Director: Wes Anderson. Group #Books by all >Genres. Tana has many ways of helping you surface just the right segment of information you need so you have a good overview, can make better decisions, and ultimately feel in control over the things you care about.
There are two main components of a field: the field definition and the field value. The field definition includes the name and type of field, as well as its configuration. The field value is the actual value of the field, which can be manually input or automatically initialized when applying a supertag.
Other than being used to record metadata attached to nodes, fields are also used in defining the query for search nodes to narrow down searches by specific field values, such as finding all #Meetings where >Attendees include the value "Jane Doe". Fields can also be searched directly by adding the field and the system field value SET, or by adding the field definition through @[field name].
Fields show up differently depending on how the nodes they belong to are viewed. In Outline and navigation views, fields are only visible when the node is expanded, but can be added to Display in view options. In Table view, fields appear as columns. See Views for more info on how to use fields in each view.
To configure a field, press on its icon to open a side panel with all field configurations.
Before you delete a field, consider whether it has been applied to any nodes or supertags. In the field configuration panel, scroll down and see the stats on how many nodes and supertags it’s been applied to.
If you have used it on 0 nodes/supertags, it’s safe to just delete the field. If you have used it on 1 or more nodes/supertags, consider finding and untagging them before deleting, or if it’s being replaced by another field, merging the old field with the new field.
When you delete a field that is applied to other nodes, these field will show a trash can icon. This follows our principles about deleting Nodes, Supertags, and Fields that have references elsewhere, which states that Tana will never delete data that is indirectly associated with another element that you delete.
To delete a field:
Option 1: Go to Field configuration panel. At the bottom there’s an action to Delete the field.
Option 2: Find the original Field definition and delete it.
Pinned fields are fields marked as important dimensions for your information. They indicate which fields you want to use most frequently for filtering, sorting, grouping, and displaying information.
Pinning a field makes it prominently visible both on supertag instances and in view options.
Pinned fields always show on top in supertag instances and are displayed with a border line around them to distinguish them from regular fields.
Pinned fields automatically appear first in the filter toolbar and view options
Unlike regular filters that disappear when removed, pinned fields remain visible in the toolbar for easy filtering access.
If you have nodes from multiple supertags in a view, and those supertags each have pinned fields configured, all pinned fields from all represented supertags will show.
Pinned fields are configured in the Supertag configuration panel. See Supertags for more information on how to mark fields as pinned in your supertag templates.
Data Validation: Based on their type, Tana will validate their contents. There are no consequences for storing information that doesn't conform with the validation rules, except for the warning that will appear in the field itself.
Plain is the most flexible type of field. It acts just like any other place in Tana where you can write anything. Ideal for data that is unlikely to be repeated (e.g., Bug description) or does not need data validation (Options, Dates, Emails, URLs, etc.).
Options let you choose from a preset of options you can select from in a dropdown menu. The presets can be defined beforehand, or auto-collected as new values are added.
Pre-determined Options: Define options directly in the field configuration. Each node becomes an option and can be reference nodes. Nested nodes are not visible.
Sources of Options: Pull in one or more nodes whose child nodes you want to populate the options list. Nodes can be created straight in the field configuration, added as a Reference to a list of static nodes, or a custom Search node.
Auto-collect Values: Turned on by default on this field type. It automatically adds new values to the option list to make it easy to reuse values.
Options from supertag creates a list based on nodes with a chosen supertag. Writing in a new value will prompt Tana to suggest that it be tagged with the same supertag.
Supertag: The chosen supertag will be suggested for new values. Nodes with this supertag will become available as options.
Date fields accept Tana dates that link to the Day node. Press space or use @ to enter a date. Click on the date to change it or right-click for options like Go to day node and Open day node in new panel.
A field setting that specifies how their content should be autofilled when a supertag is added to a node. Auto-initialization allows fields to be filled out based on the context of their creation - when they were created, where in the graph they were created, who created them, and so on. This is different from setting default values to fields in the supertag config panel, which are static.
Good to know:
Initialization expressions are convenience functions, but are not live updating. So they won't change any prior field values from before you created the initialization functions, and you can change them after Tana fills a field if they need a manual touch.
This is only triggered for fields that are part of a Supertag template. Auto-initialize will not work for fields that you use otherwise.
Initialization is only triggered when a node gets the supertag applied to it. If the supertag gets updated with a field with initialization switched on, and the supertag was already applied to nodes, these nodes will only see the field added without any content initialized in it.
(From the archive: Stian's original demo (October 2022) on how Auto-initialization works. May have outdated info.)
Available on all fields. Copies the field values from the identical field on a node earlier in the tree.
Example 1: You could have a #Quote tag with an Author field, and it could automatically initialize with the value from the Author field of the #Book that it is nested underneath.
Example 2: You could have a "Related Project" field for your tasks, and then any nested subtasks would automatically have the same related project.
Only available on Options from supertag fields. Grabs a reference to the first node with this tag that it can find earlier in the tree.
Example: You could have a #Quote tag with a Source field, which is an instance of #Source. If you tag a #Quote nested underneath a #Source node, this function would auto-populate the field accordingly.
Sets the value as the user who triggered the creation of the field.
Note: Auto-initialize to current user is a bit of a stub and there's not much you can do with this information currently. It will be picked up again for development once we start focusing on collaboration and teams.
The place you create a field becomes the primary instance of this field which carries the field definition. This can be anywhere in the graph, including inside Supertag configurations.
If you delete the field definition or its owner, and you used the field in other places, they will now appear with a trash icon alongside the name. This is intentional to prevent data from being unintentionally deleted.
Tana Template consideration: Sometimes you want the fields to live in the supertag they were created in, so if you clone the supertag definition, it clones all the fields as well. If the fields were referenced, they would remain a reference in the cloned version, which is often not desirable.
But for most situations, to better preserve the fields you create it's recommended to move them to the Schema. Also, field definitions owned by the schema have priority when searching for fields.
Adding one or more commands here will add buttons to the field that will trigger the command upon being pressed. See Commands for how to create and configure commands.
Shows for Options and Options from supertag field types.
Semantics give meaning to node relationships, and is a core concept that makes Tana powerful. Currently, semantic functions are an experimental feature in Tana.
There are usually two distinct aspects of using semantic structure: creating the structure, and running searches using the structure.
There are many different types of semantics, such as "is a", "has a", "related to", "part of" among others.
Tana has many semantic functions already baked in. Supertags express "is a" relationships, Fields express "has a" relationships with the node (and to be even more confusing, fields can also express is a/has a/state/description, expressed in human language which is not something Tana can innately understand), and the outline editor expresses a top-down hierarchy with more detail the deeper you go.
Tana offers "Part of" semantic functions as an advanced, experimental feature.
The semantic function Part of arranges information in a strict tree hierarchy, for breakdown/drill-downs. Example: An engine is part of a car. Genesis is part of the Old Testament. Oslo is part of Norway.
The Part of structure is a "one-to-many" relationship. Things can only be part of one other thing, no more. Example: A task that can belong to two projects would not be a valid "parts of" relationship. Another example: one engine can have many parts, but the parts can only belong to one engine.
Part of relationships become useful when you want to look for things that are related to parts of this structure you've created. For this we use the field operator COMPONENTS REC, meaning that you're searching components recursively based on the field value.
Example: When the Tana team reviews feature ideas, we've mapped our features and their parts into a part of semantic structure so you can attach feature requests to very small parts of the product like "extend tag". When a team member in the future reviews feature ideas for "supertags", it will return all feature requests related to supertags and any part associated with it through part of, including extend tag and more. This allows us to do data entry at very granular scales, and retrieve data at any scale that fits the need/goal.
COMPONENTS REC is an expensive search so using it for large mappings may slow down your Tana experience. We plan to improve this in the future.
We will use an example to demonstrate how this works.
1️⃣ Use the semantically connected data as field values
Let's say we are a mechanic and need to catalog every component that exists in a car so we can keep track of inventory. We have tagged every component with something like #Car part, and this supertag also has a field with semantic function Part of, where each component is mapped as part of a larger component.
We have an #Inventory supertag with an instance field called Related car part that pulls options from #Car part, and another field called Stock status where you record inventory stocks.
2️⃣ Query your inventory using the semantically connected data
You're at the engine parts store and need to know which engine parts your shop is low on. You look for all #Inventory where >Stock status: Low, and >COMPONENTS REC: Engine. This retrieves inventory items with low stock, for any car component that is part of the Engine.
The field definition is a special node that stores the settings of a field.
A field definition (1) versus a field (2) looks like this:
You can find it by putting your cursor in the field name, then press copy (Cmd/Ctrl+C) and put your cursor on an empty node and paste (Cmd/Ctrl+V).
Whenever you select an existing field to use, it is retrieving the settings from the field definition of that field.
When you create a brand new field, the field definition for that field lives in the place it was first created. If a field is created in a supertag template, it will only appear there unless you make it discoverable. This sends the field definition to the Schema.
ImprovedMark important fields as pinned in supertag configuration. Pinned fields are more accessible in the filter toolbar, display at the top of tagged nodes, and show first in all view options (Filter, Sort, Group, Display). ()
As a result of how initialization is triggered today, there is an unintentional quirk that can be used to re-initialize fields.
For fields that fall under category 2 (from the list above), it is possible to trigger initialization by applying any supertag to the node. The fields have to be in a placeholder state, or it won't work. Video demo:
Background: Early on in Tana's history the team wanted a way to find overdue tasks but there was no current way of searching for nodes with dates relative to a certain date. So, the system field "Due Date" along with the search operator OVERDUE was created specifically this reason.
But since the introduction of LT / GT (less than/greater than) operators, there is no reason to use the system Due Date field, along with the OVERDUE search operator.
A user defined field for Date or Due Date offers more flexibility:
You can use initialize feature if desired
Consistent color with other fields
You can hide the field
Example of a query to find nodes with a date that is past a certain time:
How do I share a supertag from my private workspace to a shared one?
Sep 26, 2024
Currently, the easiest and most foolproof way to do this is to not share it but instead build the supertag, with its fields and anything else necessary for the supertag to work, from the ground up in the new space.
That said, if you still want to move a supertag over that exists only in your private workspace, the main work is to ensure that there's nothing in the supertag that references something in your private workspace, otherwise it will appear as broken to others once it's moved.
It's like packaging up a zip file. You can't just zip up a bunch of shortcuts, you need the real files in there or the recipient will only see broken shortcuts.
You'll also have to remember to move over other things like field options, commands, and ensure that no saved view options contain elements from your workspace. Basically, you must ensure that nothing you're moving over from your workspace contains references from your workspace.
To bring all nodes (except system nodes) into the supertags, fields and commands you want to move, use the command "Bring referenced node here". Alternatively, you can move each necessary node separately too if you for example want the field definition to exist outside the supertag. But the key is that everything that is connected to what you're sending over gets sent over too, otherwise there will be missing pieces.
What does this warning mean: "Fields nested under other nodes or fields will not work as expected"?
Sep 26, 2024
This warning pops up in the supertag template when there are fields that are indented (another word for nested).
There are several "expected" behaviours of fields in supertags that only work when they are first-level nodes in the template, such as (and not limited by) the following:
Searching for nodes based on their field values (all #tasks with Status::Complete)
Viewing the node as a table, with fields as columns
Using fields to build title using title expressions
If you do not care for any of the above uses, you can safely ignore the warning.
Can I show an alternative representation of a field value when building a title?
Sep 26, 2024
Yes you can, with this kind of annotation:
${My field.Alternative}
Where My field is the field you want appearing in the title, and .Alternative is the name of the field within the field value you want to target instead. This is great whenever you, for example, want to swap out written-out states for emojis.
You have an Options field with some pre-determined options. For each option, add a field like Icon and put a different value for each.
When writing out the title expression in the supertag configuration, use the 1. field name in the 2. title expression format, plus add the field (in this case, "Icon") you are targeting inside the field value which will 3. make the value of the new target field appear instead.
You can go deeper with the targeting by adding more periods. So, you could have something like Field.Field2.Field3 for example.
What are field definitions and how do I find them?
Sep 26, 2024
A field definition is a special node that stores the settings of a field. It looks like this:
A field definition node
A field
To grab the field definition from a field, put your cursor in the field name, then press copy (Cmd/Ctrl+C) and put your cursor on an empty node and paste (Cmd/Ctrl+V). That gives you a reference to the field definition. Then you can run the command Bring referenced nodes here to swap the reference with the actual node.
For more information on field definitions, go here.
Fields and their field values create structured two-way connection between nodes. Structured in the sense that the connection is labeled via the name of the field.
Example: A book node has a field called Author, where you can enter a reference to any person. The relationship between the book and the person is that they are the Author.
Fields offer a variety of ways to create structured connections:
Create a Plain field and copy/paste or @-mention any node into it
Create an Options field where you can choose from a list of your choice
Create a Supertag from Options field where you can choose from a list of all nodes tagged a chosen supertag.
Fields show up in the Reference section as "Appears as [field name] in..."
This screenshot demonstrates how the different connections show up in the Reference section of a node:
How can I find nodes based on a field value of an ancestor?
Sep 26, 2024
There is no way to build a search that is able to read the fields of an ancestor node. But, using title expressions, you can grab the field value of an ancestor node and have it part of the title of the node you're running the search on, making that information searchable.
TLDR: Use the ${sys:owner} title expression to pick up content from ancestor nodes and their fields.
This solution is great for Readwise users and came about when Maggie from the community wanted to search her Readwise highlights by the tags of the article/book it was taken from.
To do this, use ${sys:owner.Field}, and repeat sys:owner as many levels up as you need to go to target the right ancestor. In the case of Readwise highlights, you usually need to go up two levels. Check out the demo video:
Now with the information you need from the ancestor node baked into the title of the highlight itself, it can be used to search and filter those nodes.
While this solution came up in the context of the Readwise integration, it is a reusable pattern that can be applied elsewhere.
Whether you're drowning in duplicate tags or struggling with inconsistent naming conventions and template structures, learn how to assess what you have, design your updated schema, and implement changes that you can catalog and keep track of, all while keeping your valuable data intact and accessible.