Intro to nodes, fields and supertags in Tana

Nodes
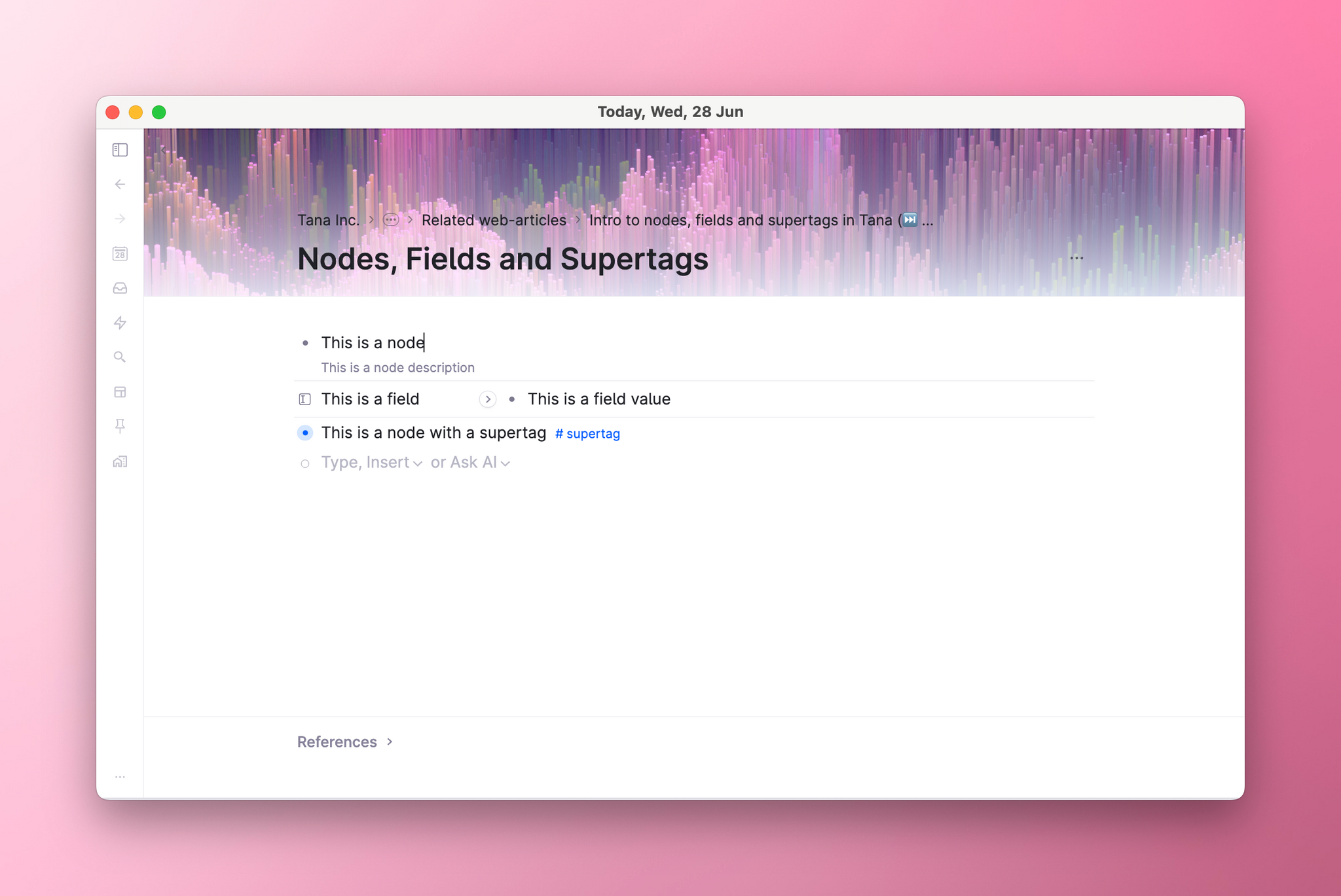
The first thing you'll encounter in Tana is the node.
In Tana, everything is a node: The fields, the views, the commands, the settings, layouts, workspaces... everything. The difference between these node types is the kind of information Tana stores in them.
Nodes are the primitives of Tana: At their core they are designed to contain single pieces of information and to exist as parts of a living information system. Living, because the information can change over time. The simplicity of the node allows it to be used as a plain bullet for taking notes, all the way to powering sophisticated daily dashboards of live information driven by Commands and enhanced by AI.
Every node is unique: Every node in Tana is given a unique ID upon creation (you can see the ID of the node in the URL bar when you zoom to it). This means that even though two nodes may look the same, they could still be considered different - just look at their IDs. The unique identification is necessary because we allow mirror copies of nodes to exist elsewhere in Tana. By editing one of the node copies, you're editing all copies that have the same ID. The copies are called references.
Nodes can have descriptions attached to them: A description appears like smaller, lighter text underneath the main node. They're great for when you want to make a small side-note about something that is related to the node itself. They are only accessible as part of the node itself, and are not possible to reference elsewhere.
Fields
This is a field that belongs to a node:
A field is a node type that contains structured content. While in regular nodes you are encouraged to type anything, a field has criteria for what it's looking for you to input. Structured content looks like "Author:: James Clear". Often called metadata or attributes, they require a name and you get to pick what datatype you want to store in it. Tana will loosely validate the datatype, nudging you to pick the right type of data, but also allowing you to enter different types of data if that's what you need in one particular instance. To see all field types, check out the documentation on Fields (link to come). The most used ones are:
- Plain: Accepts any and all types of information. The most flexible field type.
- Options: Accepts a pre-defined list of fixed options, or a reference to a node whose children you want to use as options.
- Instance: Accepts a list of options populated by a supertag of your choice
- Date: Accepts a date. Hit spacebar to pick a date or use @-mention to reference a date (you can use natural language like "next Friday" to get the proper date)
- Checkbox: Turns field into a checkbox
Fields are like the columns of a database. In database speak, whereas a row/item is equivalent to a node, a column is equivalent to a field. Our Table view mimics this view:
Another way to think of it is in terms of "has a". A node "has a" field. A book has an author. A project (node) has a team lead (field). A paper "has many" topics.
Do not mistake attributes for contexts. One could say that an inventory "has many" items. But is "inventory" one of many objects of its kind, and are the items its attributes? We would see "inventory" more as a context, as a place you go to find a list of all items. The purpose of an inventory can, for example, be fulfilled quite well by our Search nodes, which you can learn more about here and here.
At the end of the day, a field says something enduring about the parent node. It is an attribute, or a piece of metadata that helps flesh out other important information that is related to the node. A book (node) will always have an author (field). A product (node) will always have a barcode (field). A bug will always be related to a product feature. A recipe will always have ingredients. Which brings us to...
Supertags
This is a node with a supertag called #quote:
Supertags give you superpowers when it comes to systematizing structure. In the section above, we explored how certain objects have enduring qualities and attributes. This leads us to wanting all our #books to have the same fields, but different from our #projects, and different from #people etc. All nodes with a certain supertag will inherit the fields and content defined in the supertag configuration, making it very easy to keep a structure consistent everywhere.
Supertags apply to the whole node, and define what it is. There is a big difference between how tags are used elsewhere versus here. While you may be used to adding tags as a way to stick keywords (#rome, #friyay, #vanlife), states (#toread, #processed, #important) or even objects (Saw #Melissa on our way to #Comicon) to ones notes, in Tana, a supertag defines what kind of object that node is. Therefore, the supertag gets applied to the whole node. Is it a #person, #historic figure, #actor, #project, #journal, or #meeting, like that.
If we take the example above, the way we would rewrite "Saw #Melissa on our way to #Comicon" in Tana would be like this:
- Saw
@Melissaon our way to@Comicon#log
And the @ symbolizing that you're referencing nodes from somewhere else that look like this:
- Melissa #person
- Comicon #event
Like how fields work with "has a", a supertag works with "is a". This node is a recipe. That is a task. You cannot say, for instance, "this node is a processed". Processed is a state, or rather, an attribute to the node which could be defined through a field called "Status" or similar which has options like Inbox/Next/Processing/Done/Archive. Now, don't start looking around you and think "oh, this is a #coffeecup!". Only perhaps if you have a collection of kitchenware you're cataloguing in Tana and #coffecup happens to be a major category you want to keep track of. In all other cases, do this exercise within your notes, and try to think about what you're taking notes on, what process they're part of, and where you want to see them again.
Indeed, use supertags whenever you want to collect something. To collect things means you'll likely be seeing many of these objects in your notes. For example, an #agenda-item can be a good supertag. Ideas for an agenda item can pop up at any time. Just write it down and pop a supertag on it, and you can have all agenda items made the past 7 days collect into the next #weekly-meeting so that your agenda pretty much makes itself. This is the Tana way.
Next steps
Nodes, fields and supertags are some of the most important features of Tana. They help set up the structure in our information that gives us control over when we want to see it again and how. For more on that, we encourage you to check out this article on Supertags, Search nodes, and Views as it builds upon the foundation that we have laid here.